MM-LLMs: Recent Advances in MultiModal Large Language Models
Paper link: https://arxiv.org/abs/2401.13601
Goal
整理了 MultiModal Large Language Model(MMLLM)的發展和研究現況,包含模型訓練架構及範式、State-of-the-art(SOTA)的 MMLLM 有哪些、其架構的組合為何等等,並點出未來潛在的研究方向。
Training Architecture
Overview
模型訓練架構可參考以下這張圖: 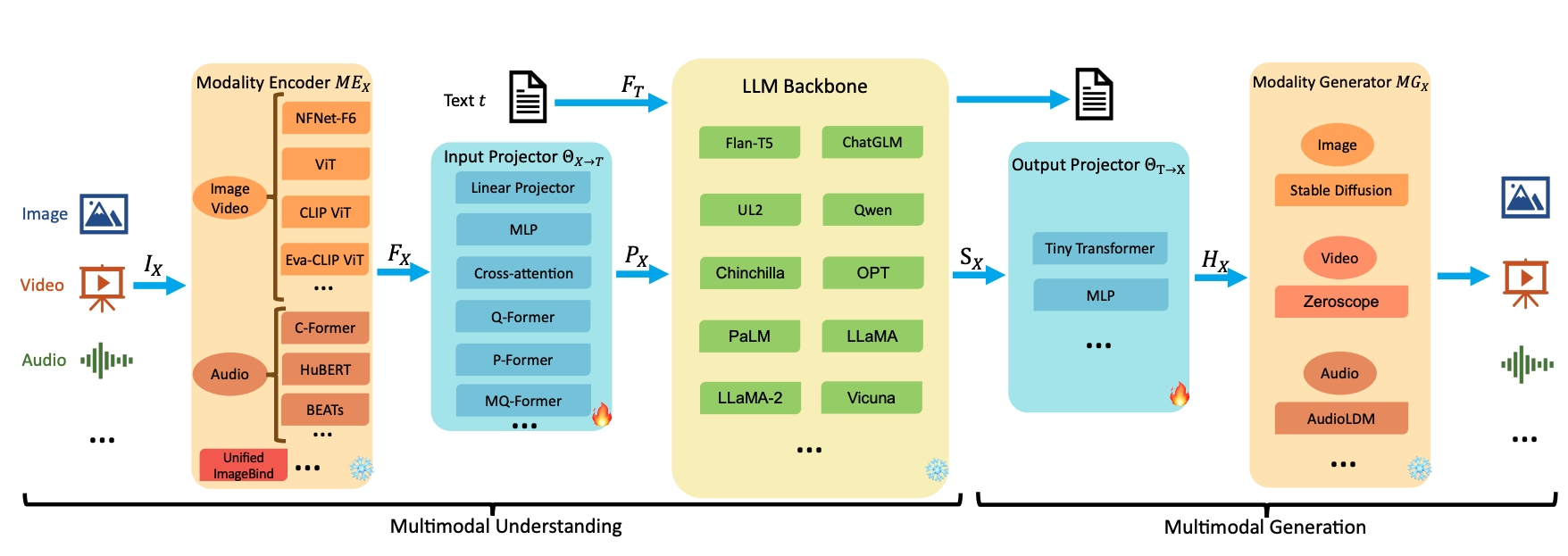 General model architecture
General model architecture
如圖所示,基本上可分成兩大部分:
- Multimodal Understanding
- Multimodal Generation
並由5個 component 組成:
- Modality Encoder($ME_x$)
- Input Projector($\Theta_{X \to T}$)
- LLM Backbone
- Output Projector($\Theta_{T \to X}$)
- Modality Decoder($MG_x$)
若以 $X \to X$ 表示模型的 I/O(X代表任意模態,可能是 I: image、V: video、A: audio 或就是 T: text), Multimodal Understanding 的範疇即可表示成:$X \to T$。
Bridge between Embedding and LLM:Input Projector
一般而言,為避免影響 LLM 的既有能力,或者說造成 Catastrophic Forgetting,在訓練時會將 LLM 的參數凍結(可看到 LLM Backbone 右下角以 ❄️ 表示),而這時 Input Projector 就負責扮演將 Modality Encoder 的結果( $F_X$ )去適配 LLM 輸入的重要角色。負責轉換的這過程是需要訓練的,故可看到圖中 Input Projector 的右下角有🔥,表示這部分的模型參數是 learnable。
Input Projector:Cross-attention-based vs Auto-regressive-based
Input Projector 可分成兩種 setting:
- Cross-attention-based
- Auto-regressive-based
Cross-attention-based 的代表 MMLLM 是 BLIP-2,將 $F_X$ 透過 Q-Former(具體而言是 $BERT_{base}$)和 text representation 去交互作用。 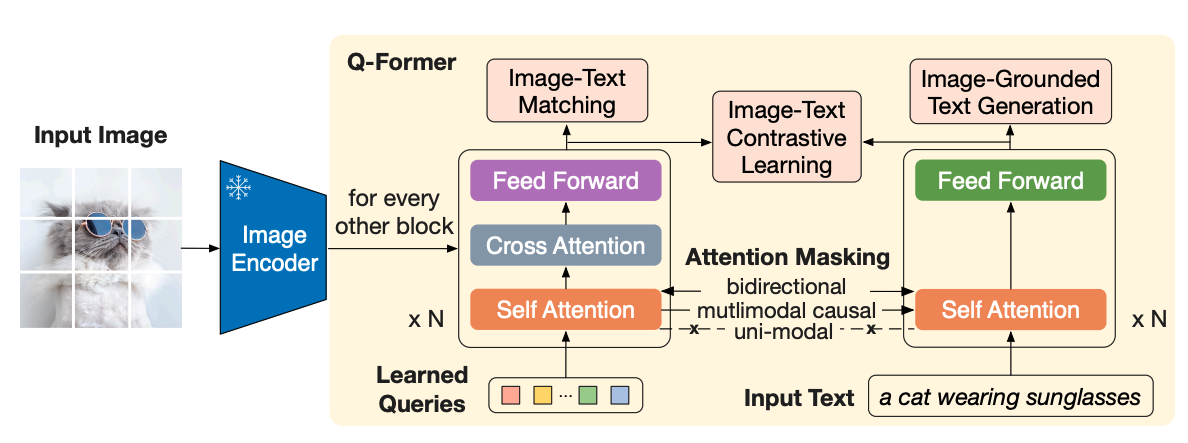 BLIP-2
BLIP-2
Auto-regressive-based 的代表 MMLLM 則是 VILA,這個方法較為直覺理解,即是把 Input Projector 視作一種 tokenizer,將 $F_X$ 再轉成 LLM 可接受的 token sequence。如下圖表示,visual tokens 和 textual tokens 可彈性放置以支援任意的 interleaved image-text 輸入。
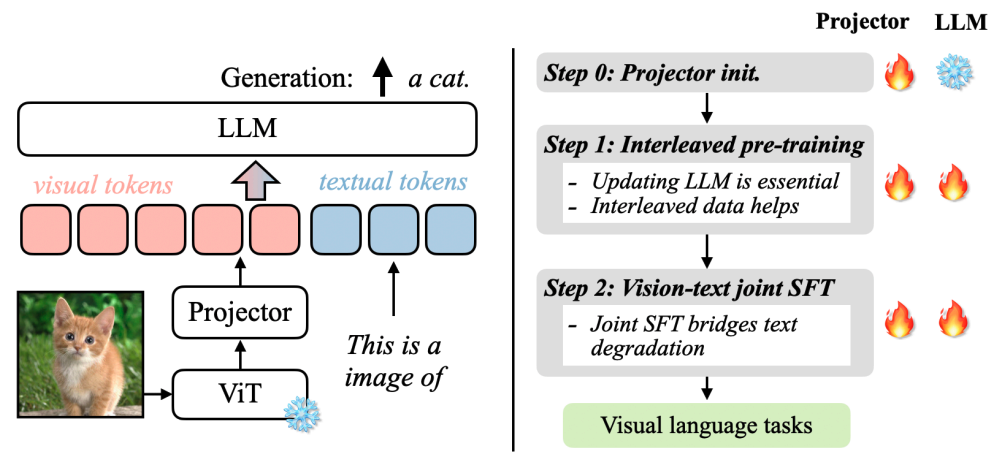 VILA
VILA
Training Paradigm
和 LLM 的訓練範式相同,也有 Pre-Training(PT)和 Instruction Tuning(IT)兩大階段。
Pre-Training(PT)
PT 所使用的訓練資料基本上是 X-Text pair 的形式,其中 Image-Text 除了 pair 之外(<img1><txt1>),還有像是在介紹 VILA 時提到的 interleaved image-text 格式:<txt1><img1><txt2><txt3><img2><txt4>。
Instruction Tuning(IT)
IT 一樣有兩個步驟,Supervised Fine-Tuning(SFT)和 Reinforcement Learning from Human Feedback(RLHF)。SFT 將部分的 PT 訓練資料轉為 instruction-aware 的格式,以 Visual Quetsion- Answering(VQA)為例,模板可能為:
<Image>{Question} A short answer to the question<Image> Examine the image and respond to the following question with a brief answer: {Question}. Answer:
RLHF 接著 SFT 後,根據模型的輸出,藉由 Natural Language Feedback(NLF)更進一步微調。Framework 可參考:RL4F、LLaVA-RLHF 和 DRESS。
Training recipe without bells and whistles
從 VILA 圖的右半邊可以看到,LLM 在 PT 和 IT的階段,並非 frozen 的狀態,主要是認為,雖然 frozen LLM 在 zero-shot 的表現不錯,但涉及到 few-shot, 也就是 in-context learning(ICL)的任務時就有差了。 也談到 interleaved image-text 比起 image-text pair 更能幫助模型,主要是後者的 caption 大多較為簡短,和原先 LLM 所訓練的 text-only corpus 的 distribution 有所落差,會造成模型 Catastrophic Forgetting,相比之下 interleaved image-text 通常 text 的資訊較為豐富。而實驗證明兩者融合更能增加資料的豐富度,達到更好的表現。PT 階段後,Joint SFT 提到除了使用含有 Image-Text 的 data fine-tuning 外,text-only corpus 也應加進去一起 SFT,不僅可有效避免 LLM 在 text-only 的任務上表現降低,也能協助其找回 instruction following 能力,提升在 visual task 的表現。
SOTA MMLLM
Component Anatomy
MMLLM 以及其 component 一覽可參考下表: 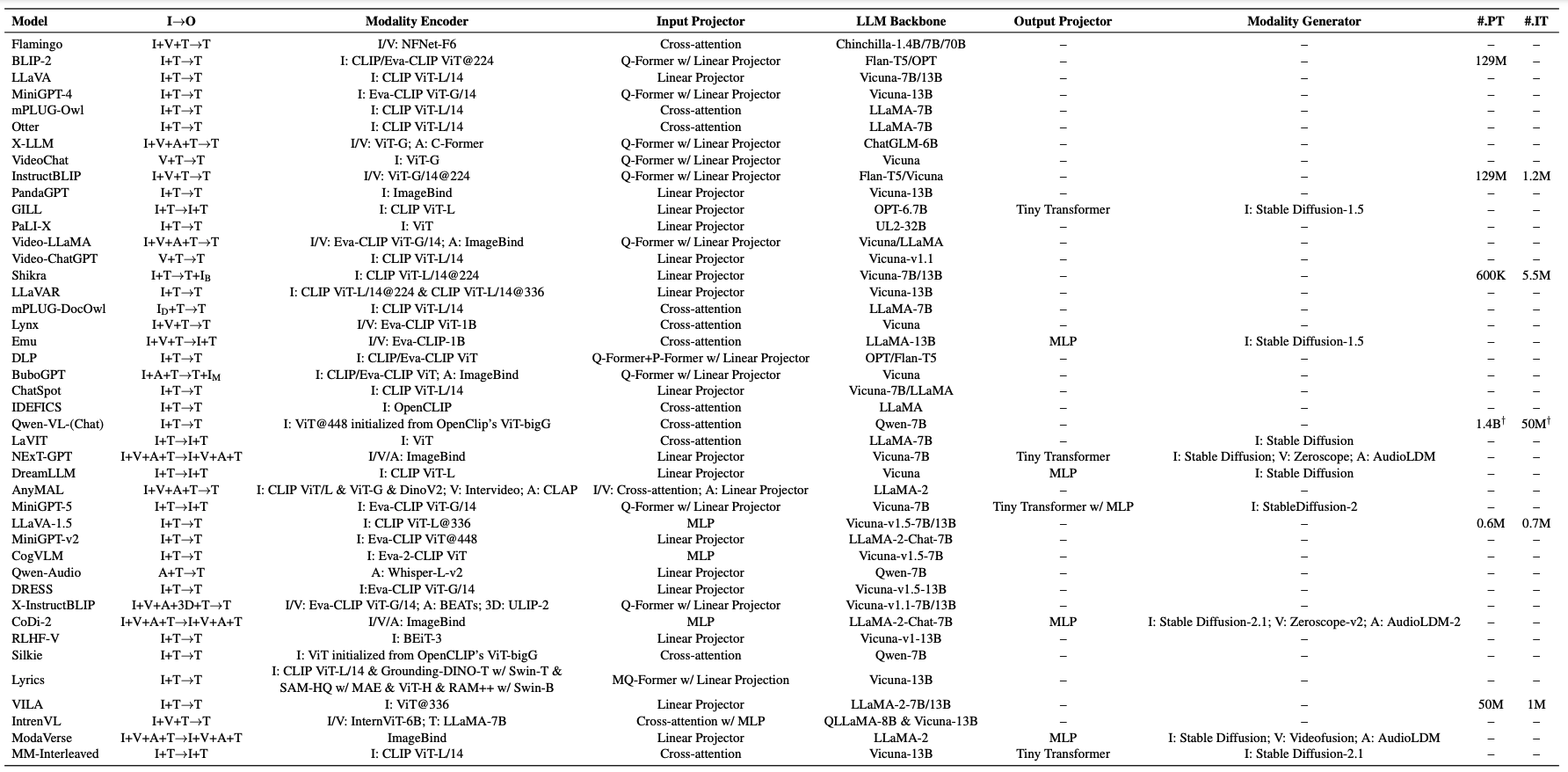
Trends
- 訓練範式的進展:PT $\to$ SFT $\to$ RLHF,更加增強模型的對話能力
- BLIP-2 $\to$ InsturctBLIP $\to$ DRESS
- 更高品質的訓練資料
- 更有效率的訓練方式,將 Input Projector 化繁為簡,從複雜的 Q-former 到簡單的 Linear Projector
Future Directions
More Challenging Benchmarks
MMMU 和 CMMMU 代表了 Massive Multi-discipline Multimodal Understanding 的英文和中文版本,由大學程度的六大學科多選題組成,包含:藝術設計、商業、科學、健康醫學、人文社會和科技工程,涵蓋30種主題,以及起碼30種的圖片類型,例如:圖表、流程圖、地圖、表格、樂譜甚至是化學結構式。可看成是 vision 版本的 TMMLU+。
 MMMU
MMMU
Mobile/Lightweight Deployment
模型本身如何輕量化已是一個重要的趨勢,如何在像是行動或物聯網等計算資源有限的裝置上部署,在減小模型規模的條件下同時還能保有一定性能,是更符合商業需求的課題。MoE-LLaVA 將 MoE-Tuning 引入到 MMLLM 的範疇當中,以大約 3B 的 activated 參數量,可達到跟 7B 大小的 SOTA 模型差不多的表現。 MobileVLMV2 則是進一步從 Input Projector 著手改良,所提出的 LDPv2,其中的 positonal part 相比前代減少99.8%的參數量,大幅增加推論速度。
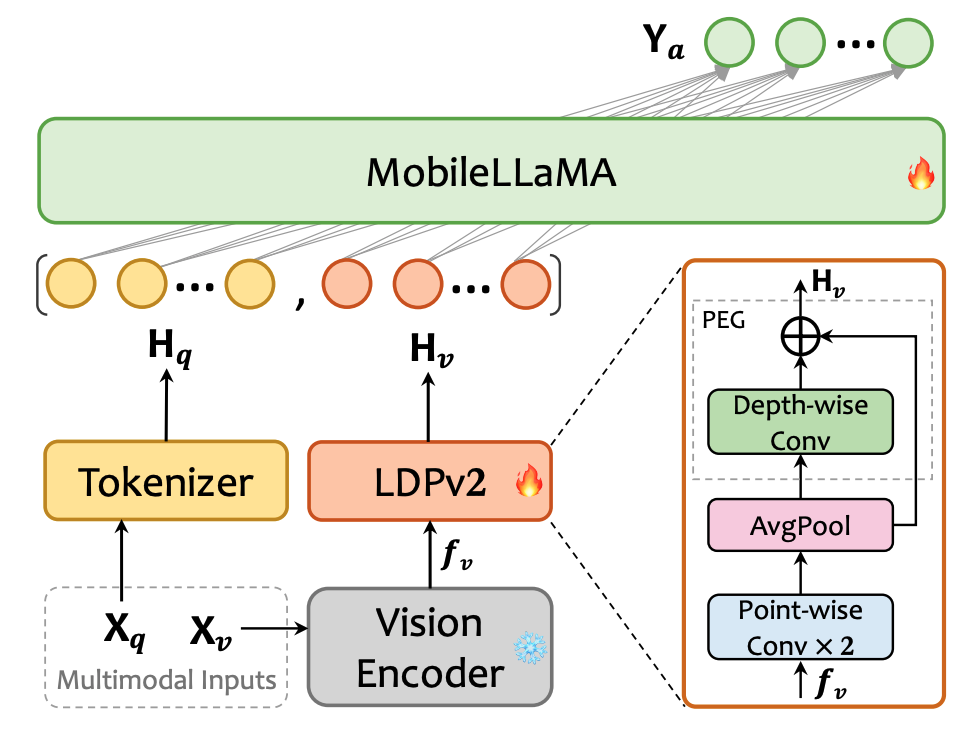 MobileVLMV2
MobileVLMV2